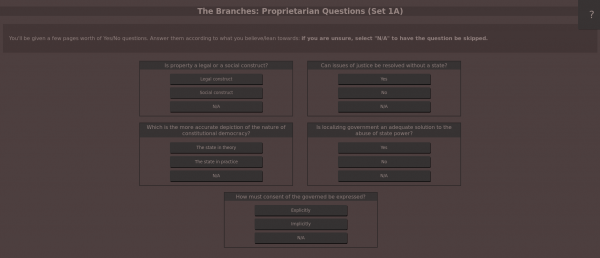
The following is part of a larger series discussing the ongoing development of PoliTree, an attempted political-compass killer which has been way too long in the making. To find out more, visit the introduction.
Well, that hiatus went on much longer than expected. However, believe it or not, progress on the site is officially back in full swing. One of the busiest periods of my life is finally over, other projects I’ve had on the bench forever I’ve gone ahead and wrapped up, and following a year of learning/experimenting with web-development I have a much clearer plan for how the actual implementation of the rewrite is to be done.
In the month of August, I have:
- Ported the repository to Codeberg, a software forge which is more aligned with the values of the free-software movement as a whole. This also conveniently gave me the excuse of a blank slate to begin the rewrite on, and to actually make use of Codeberg’s features. There are now issues, milestones, and labels to allow me to list out each problem I will have to tackle and the progress I am making. This is infinitely less taxing than the old way, where I kept it all in my head.
- This, alongside progress on documentation is important, because I am bringing on another developer, XYZInferno, to assist me in the rewrite process. The goal is that by more clearly documenting the model and all the various conventions I have developed along the way, this will make it more accessible to others to assist me, and hopefully upon release make it easier for people to understand and mod.
This month has really been preparing for the rewrite, and I have dubbed the milestone for these tasks Version 0.7.0. The rewrite will be Version 1.0.0. For version 0.7.0, in addition to the above, there were two other major tasks I began on:
Every single reference has been ported over to IPFS, a peer-to-peer distributed filesystem. I have been planning this for a while, as IPFS files have no central host. Rather instead, you provide a hash of the file’s contents, and then it will treat that hash as an “address” by which it can look to see if someone on the network is hosting said file. This someone doesn’t have to be Github, it doesn’t even have to be me, it can be anyone. In addition to reducing the filesize of the repository immensely, this will also make the site far more censorship-resistant, a concern that has been in the back of my mind since the beginning. If the references ever get taken down on one node, someone else can host them, and the site’s links won’t break.
I have also gone ahead and used this opportunity to begin adding ePUBs for references, no longer will you be restricted to PDFs (assuming an ePUB exists)! I’ve always been a fan of e-readers, so I’m hoping others will find it useful too.
And finally, the big one: every component of the site structure is being converted into a JSON. At the pace I’m going, I’m slated to finish this task by early September. I cannot stress enough how time consuming this is. I am about 2/3 of the way done and I have written 209 JSONs by hand. There will be around 300 JSONs by the end I’m estimating.
But to explain what I’m doing and why. The entire site relies on this sort of tree model, where one element (say, a Leaf) will have various properties (a color, a name, books associated with it) that are referenced by multiple children elements (say, Branches) and thus have their information duplicated across multiple pages (think how each Branch page has the same Leaf references). You can even see this in how every page follows a common template for its layout/styling, just with different words on each page. When I began creating this site all those years ago, I hardcoded everything. Want to change a book title or a leaf name? Have to do it everywhere.
The more effective way, and the way that will actually allow me to dynamically operate on data and dynamically link stuff together, is to take the information contained in every relational element of the test structure (Questions, Clusters, Leaves, Branches, References) and put them into a data-store which code can actually operate on, as opposed to putting them in scattered HTML. JSONs are simple and local, so I figured they were the best option. The structure of one of these JSONs may look like the following:
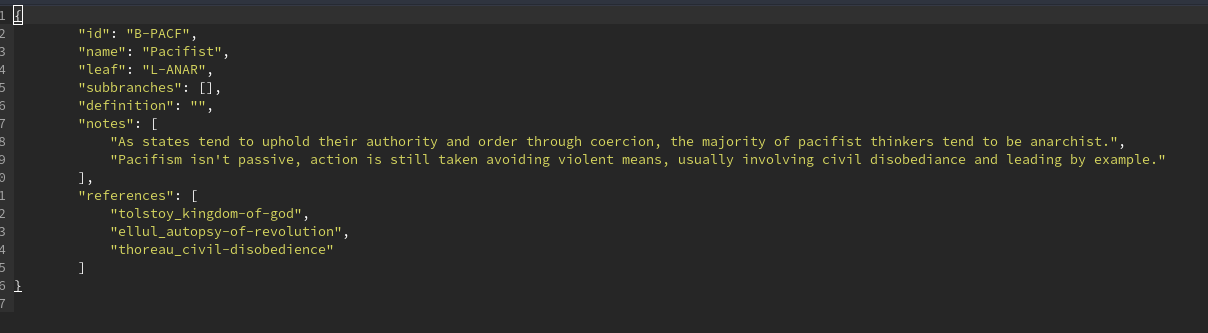
As you see, each element has an ID. These IDs are designed to be entirely unchangeable so that other elements can reference them. I know what Leaf the Branch belongs to because I can reference the ID in a property. One of the problems I also ran into earlier is that whenever I wanted to rename a Branch or Leaf, I’d occasionally find various links broken as what referenced what was also scattered across the site. As name is a separate property, anything can be renamed now without worry. And by changing any of these properties, everything in the code which references it will pull the new value automatically. And if I do need to change how the data is formatted, I’m at least able to write an automatic script now to operate on the JSON data rather than having to do everything by hand.

And, as you can see, the IPFS hashes are contained as a property of the reference. The IPFS gateway will be stored separately in the config, so that also can be changed with ease.
As for future plans, my current idea for the site is to use a Flask backend (as I’m familiar with Python and JS is very weird about handling local JSON data from my experience) in combination with a CSS module library like Bootstrap or Pure to allow for less headaches when doing layout and easier responsive design. The main goal for 1.0.0. is to have a fully functional test which can easily be run on either mobile or desktop. Using modules will probably mean the site will lose its’ weird visual distinctiveness, but who knows, maybe I can make it brown some other way 🙂
Blogger and software engineer. I write on tech, politics, and theology.