The following is part of a series of blogposts in which I discuss my design decisions when making the PoliTree: an attempted political-compass killer which has been way too long in the making. To find out more, visit the introduction.
As the test has gone through multiple redesigns and myself a lot of development over the years, the contents of this post may or may not apply to the test in its modern form or my current views on its design.
Despite not penning an update on the official timeline, I’ve spent the months of December and January mostly attempting to grind through the remaining results pages and getting together the sources. While it has progressively gotten more difficult as I’m forced to finish the pages I’ve put off for a while, I am really happy to say that I have finished 32 out of 34 of the results pages, along with their respective reading sources.
So as we near the end of this leg of the development process, I do want to discuss one more thing related to my design choices for this project: how I go about distributing the reading material suggested by the site.
The Fundamental Principle
Above all else, one of the key principles underlying this project is the absolute freedom of information. The assessment itself serves to deal with the more intellectual barriers to accessing information (such as the sifting of information), and it’s the same principle that has led me to put just as much time into making the information itself accessible as much as I put into the website itself.
A lot of the works listed are primary sources, seminal texts and cornerstones in the political thought that makes up the world today. But it is not enough for the information to just exist if people are unable to find it; an integral part of learning is also the presentation of information, and this is where I feel I have to step in to ensure that the information is able to get to the person who is willing to take the step to learn about these subjects.
The main obstacle to achieving this is intellectual property and the commodification of information. It cannot be understated how quickly intellectual property is becoming a major industrial force: to get a full grasp of the industrial factors behind IP, I highly recommend reading this 2016 report by the USPTO.
For those too lazy to read, I’ll give you a rundown of a few of the most interesting insights:
- Currently trademark and copyright-intensive industries make up a combined 40.4% of the total United States GDP.
- Businesses in the field of selling newspapers/periodicals/books have netted about $2.9 billion worth of exports in the year 2012.
- Over the course of the Information Age, copyright-intensive industries have shown employment growth greatly outperforming other sectors, whether they be reliant on trademarks or no IP at all. (see below)
- IP-intensive industries constitute about thirty percent of all employment nationwide.
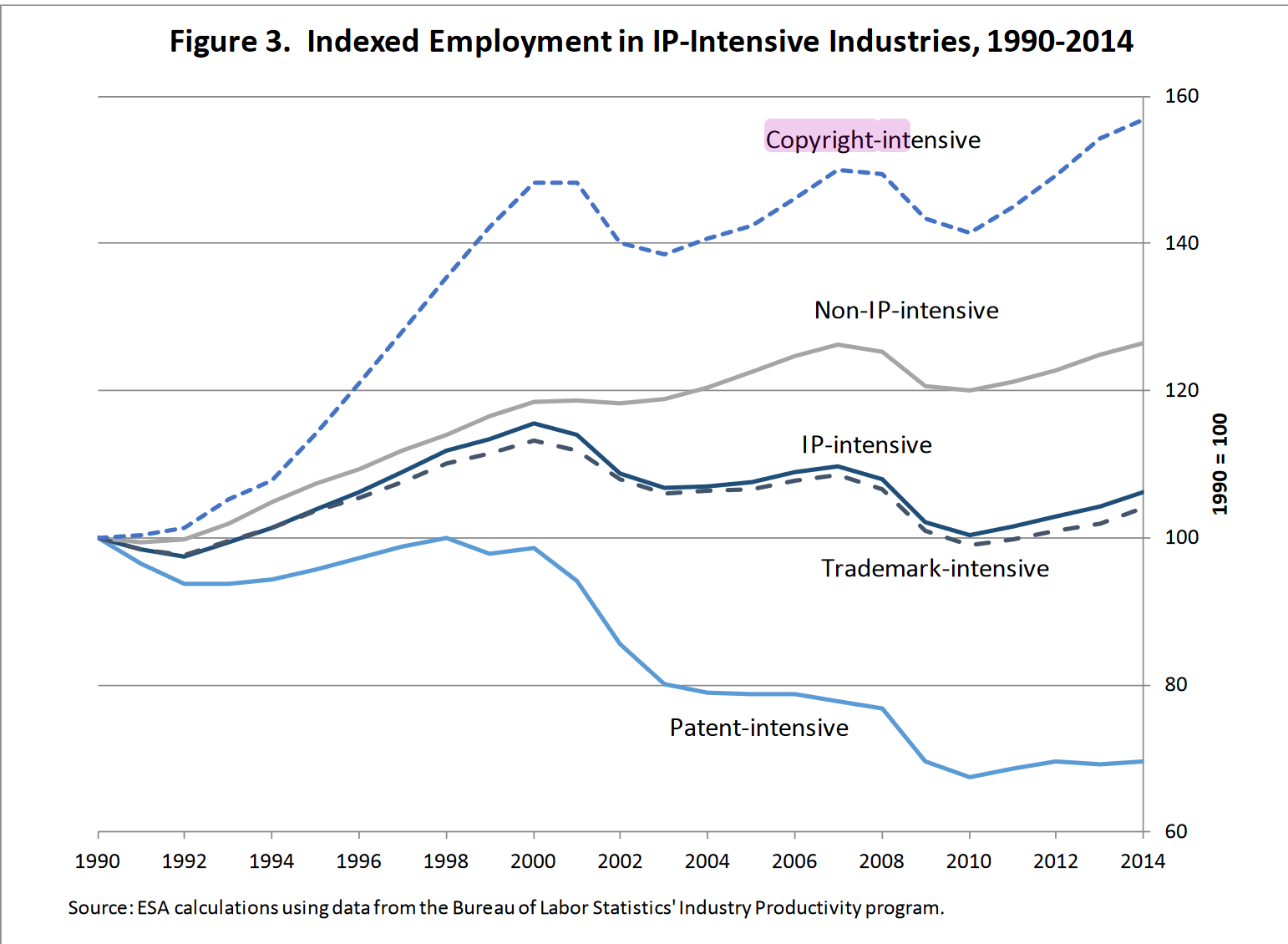
When we stop looking at the larger picture, even as individuals we can see the effects. Search up any of these books, and most of the time you’ll either be redirected to the Amazon page to buy it, or if you’re less lucky, asked to subscribe to an academic database to access it. Articles discussing said works typically link to store pages, and so do general directories.
And this is where the exclusive nature of intellectual property begins to rear its ugly head: through the constant encroaching of DRM and aggressive copyright enforcement, information is quickly being walled off. You may be a person who cannot afford to pay, a person in a country which is unable to access the work to due regional restrictions, or even a historian in the far future struggling to recover a cultural artifact due to its limited availability.
The internet is an absolutely powerful tool, with the ability to connect people and ideas in a way never thought possible before: this could mean learning a new skill, meeting people with completely different experiences than you, or using digital tools to create information of your own. But all of this depends upon the freedom of information.
It is because of this, I have made the effort not just to create a novel political model, but also use the opportunity to help ensure that information remains free from the industrial stranglehold that remains on it.
My Current Strategies
There are times where I am lucky and am able to get my hands on a standard PDF for a book. Online libraries which share this same goal, such as Archive.org, the Marxists Internet Archive, The Anarchist Library, and Project Gutenberg have been invaluable tools to ensure this project’s completion. Currently the vast majority of the texts linked are standard PDFs, obtained through varying degrees of effort and looking.
However, no matter my determination, there are still places where I hit a roadblock: accessing digital copies can occasionally be outright impossible sometimes, especially with older and more obscure texts. As an alternative approach, I’ve worked on attempting to manually transcribe physical copies to LaTeX. While the results have come out very well, considering LaTeX is an incredibly versatile program, there still is the issue of how incredibly time-consuming it is.
If you would like to see a sample of this, I have already transcribed the first nine pages of The Futurist Cookbook. I may return to this approach, as I still believe it holds promise, but I think I will need something else for the time being.
Deciding on a Stopgap
I’m simply using this section to write down what is going through my head right now, even if the ideas themselves aren’t completely thought over or fully formed. After all, the main reason I write these short commentaries on the creation process is usually to outline my thought process when faced with crossroads of design decisions. This is no exception.
As neat of a solution as transcribing books is, as I close in on the end of this stage of development, I have to be realistic with how I’m allocating my time. Simply giving the ISBN would probably be too confusing for the end-user, especially considering the point of this is for me to expedite the research process for them. I still hold strong to not linking to storepages, and I do not see myself backing down on that any time soon.
When deciding what to do next, I was faced with two options:
- Link to a listing of used books, on a search engine such as eBay or AbeBooks.
- Link to a search engine for public libraries and their stock, such as WorldCat.
I initially considered the first option, since while used books cost money, they aren’t subject to industrial forces in the same way a new book is. There’s a distinction which I think can be best explained by the concept of CMC/MCM circuits as laid out in Capital Volume I:
The simplest form of the circulation of commodities is C-M-C, the transformation of commodities into money, and the change of the money back again into commodities; or selling in order to buy. But alongside of this form we find another specifically different form: M-C-M, the transformation of money into commodities, and the change of commodities back again into money; or buying in order to sell. Money that circulates in the latter manner is thereby transformed into, becomes capital, and is already potentially capital.
What, however, first and foremost distinguishes the circuit C-M-C from the circuit M-C-M, is the inverted order of succession of the two phases. The simple circulation of commodities begins with a sale and ends with a purchase, while the circulation of money as capital begins with a purchase and ends with a sale. In the one case both the starting-point and the goal are commodities, in the other they are money. In the first form the movement is brought about by the intervention of money, in the second by that of a commodity.
In the circulation C-M-C, the money is in the end converted into a commodity, that serves as a use-value; it is spent once for all. In the inverted form, M-C-M, on the contrary, the buyer lays out money in order that, as a seller, he may recover money. By the purchase of his commodity he throws money into circulation, in order to withdraw it again by the sale of the same commodity. He lets the money go, but only with the sly intention of getting it back again. The money, therefore, is not spent, it is merely advanced.
In simpler terms, because a CMC circuit begins and ends with a good, it is unable to loop. The commodity sold in a CMC ends up being replaced by another commodity, preventing an industry from being able to form around this relation.
Selling a used book seems to mirror this, however, there is one issue. Something other than the book is industrialized, and that is the service associated with online reselling. Going to such an effort would be futile if you still found yourself promoting something else. But more importantly than that, online reselling still finds itself setting up geographic and financial barriers.
For now, I think it is best to link to a library database like WorldCat, but even that poses barriers, mainly in convenience and once again, geographic ability. It’ll most definitely have to be a short-term solution, and I’m probably going to continue exploring ways to expedite the transcription process.
How You Can Help
Another key component of the internet is collaboration; people who have access to different resources and have different skills are able to work together towards a common goal.
If anyone is interested in helping me find references, I have posted my major dead-ends under the “Wanted Reference” tag on GitLab. I accompanied each issue with whatever leads I have found in my research, and if you are able to figure out how to acquire these missing pieces, please let me know.
The best way to contact me is through my Mastodon, if you have any ideas or questions.
Blogger and software engineer. I write on tech, politics, and theology.


